
Data quality is a fundamental pillar of data governance, ensuring that data is accurate, consistent, reliable, and available for decision-making. It provides the trustworthy foundation necessary for organizations to build strategic initiatives, optimize operations, and gain competitive advantages. Without high data quality, data governance frameworks can falter, leading to flawed analyses, poor decisions, and increased risks.
In data governance, data quality encompasses accuracy, completeness, consistency, timeliness, and validity. These dimensions ensure data accurately represents real-world entities and aligns with organizational standards. Robust data quality practices within governance frameworks enhance data’s strategic value, involving processes for data cleansing, validation, and enrichment, along with clear accountability and ownership. Thus, data quality is crucial for achieving business objectives and sustaining long-term success.
Data quality is a significant concern for organizations as they directly impact decision-making, operational efficiency, and overall business performance. One of the primary issue is the presence of inaccurate or incomplete data, which can stem from human error, outdated information, inconsistent data entry practices or while the data is transformed.
Poor quality data can lead to flawed analytics, misguided strategies, and ultimately, financial losses. Ensuring data accuracy requires robust validation processes, regular audits, and the implementation of standardized data entry protocols to minimize errors and maintain data integrity.
In this article, we’ll showcase a range of data quality checks using the Databricks platform as an example to illustrate how to effectively maintain and enhance data quality. We will delve into how the Medallion architecture facilitates effective data management and addresses common data quality issues.
Databricks is a unified analytics platform designed to accelerate innovation by bringing together data engineering, data science, and machine learning workflows in a collaborative environment.
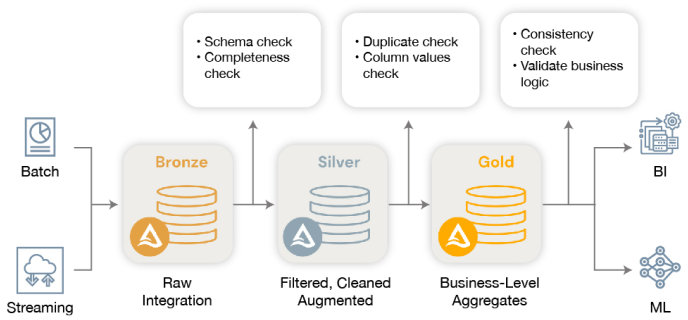
The Medallion architecture is a data management framework that divides data processing and storage into three distinct layers: Bronze, Silver, and Gold. Each layer serves a specific purpose in ensuring data quality, efficiency, and usability within an organization’s data ecosystem.
Bronze Layer (Raw Data Ingestion): The Bronze layer is where raw data from various sources is ingested without any transformation. It acts as a landing zone for all incoming data, preserving its original form.
Schema Check: Ensure that the schema of the processed data matches the expected schema and provides the mismatched columns.

Data Completeness Check: Ensure that all the source data has been captured on the target

This will succeed when the source and the target rows match.
Silver Layer (Cleaned and Enriched Data): The Silver layer focuses on cleansing, transforming, and enriching the raw data from the bronze layer to improve its quality and usability. It prepares data for downstream analytics and reporting.
Duplicate Check:

Ensure that duplicate records are identified and handled appropriately.
This will return Pass and return empty information about the duplicate records as there would be none. Now we can choose to write these records in a separate directory or choose to ignore them completely and it will depend on the specific use cases.
Column Value Check:

This test case checks for any discrepancies between the column values which were not supposed to changed after the transformation of the data from one layer to another.
Gold Layer (Aggregated and Business-Level Data): The Gold layer houses refined and aggregated data that is optimized for business intelligence (BI) and decision-making purposes. It represents a curated dataset that reflects the organization’s key metrics and performance indicators.

Data Consistency Check: Ensure that the start values are less than the end values where applicable in the data set.
By leveraging the aforementioned examples, we can ensure data quality post-ingestion, validating that the data remains intact and as expected. Additionally, we can confirm data completeness and validity after referencing and joining tables. It is important to note that processes such as schema validation, null checks, and duplicate checks are not confined to a single layer but are generally applicable across all layers of data processing.
The flexibility of this design also allows us to either halt the entire pipeline or generate alerts in scenarios where it is not necessary to stop data processing.
Outlined below is the high-level framework that enables us to verify data integrity between layers, ensuring that BI and ML workloads deliver business value by being fed with high-quality data.
Code examples above illustrate only a small part of the solutions we provide to enhance data quality. They showcase some fundamental techniques, but our expertise encompasses a wide range of strategies tailored to your specific needs. We can offer customized support and innovative solutions to address your unique data challenges and are committed to helping you achieve optimal data quality and drive actionable insights.
Data quality is paramount and must be prioritized from the outset when developing data platforms. It should be integrated as a core component, not an afterthought. Databricks and the lake house architecture offer significant benefits and best practices for enhancing data quality. However, there is no silver bullet, customization is essential to meet specific use cases.
Databricks provides various tools and mechanisms, including delta format configuration and specialized features, to address data quality issues. While it can’t solve all problems alone, these tools enable the creation of a robust data quality framework. By effectively utilizing these resources, we can ensure our data remains accurate, reliable, and of the highest quality for business needs.
For more information on our services and how we can assist you, reach out to mahesh.shankar@thoughtswinsystems.com. Let’s revolutionize your data management process together.