In the engineering industry, digitizing old engineering diagrams is a significant
challenge, especially when scaling operations to manage millions of drawings.
Essential information such as the title, drawing number, revision number, and tags must
be extracted when digitizing engineering diagrams.
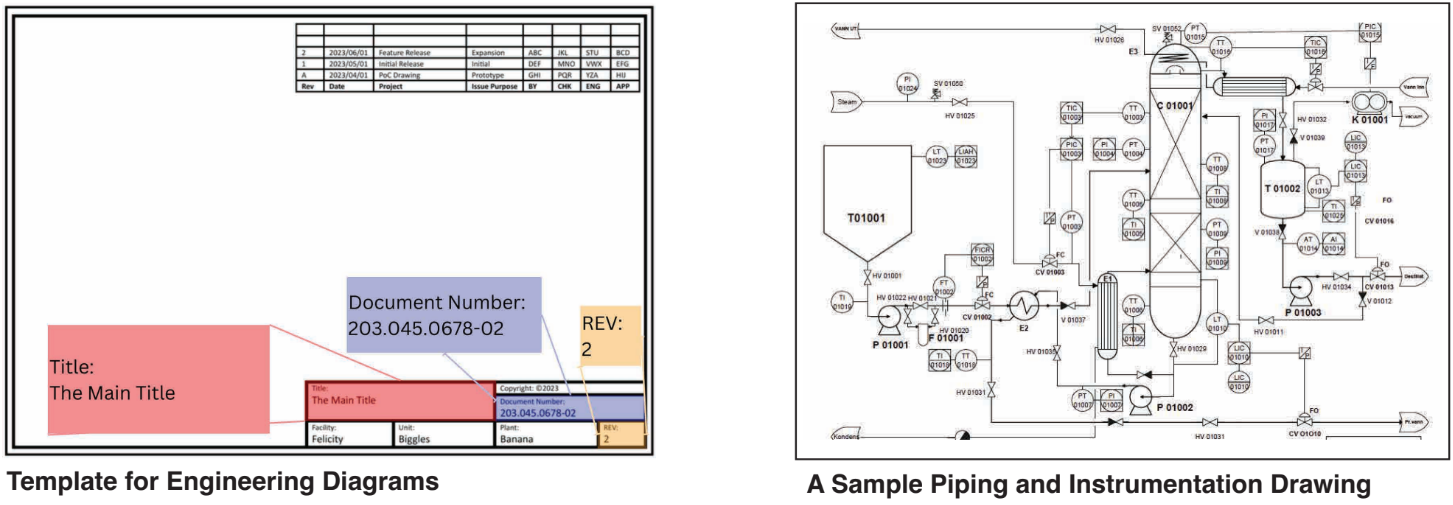
For example, in the diagram template below, the title, drawing number, and revision
number might be “The Main Title,” “203.045.0678-02,” and “2,” respectively. Despite
the apparent simplicity of this task, the global variety of templates, each potentially
containing thousands of diagrams, presents a formidable obstacle.
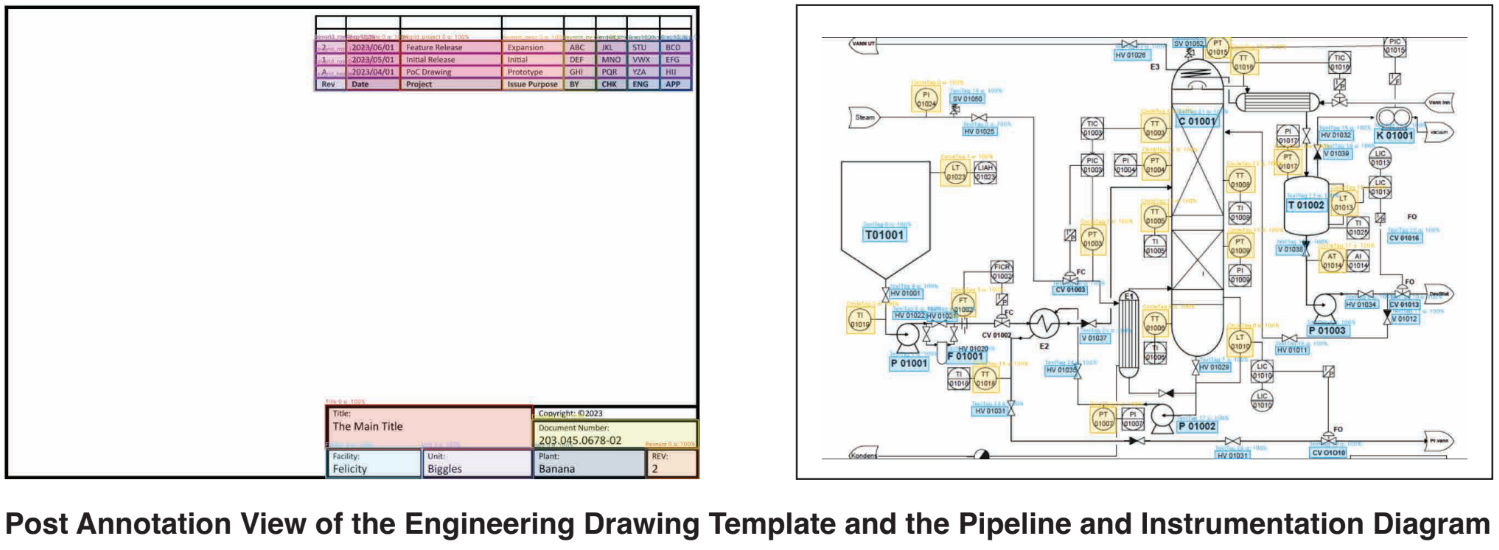
Furthermore, the existence of component tags in such drawings, as seen in the sample
Piping and Instrumentation Diagram, requires meticulous analysis, potentially straining
the eyes and constituting a heavy task for a single person, not the best use of their time.
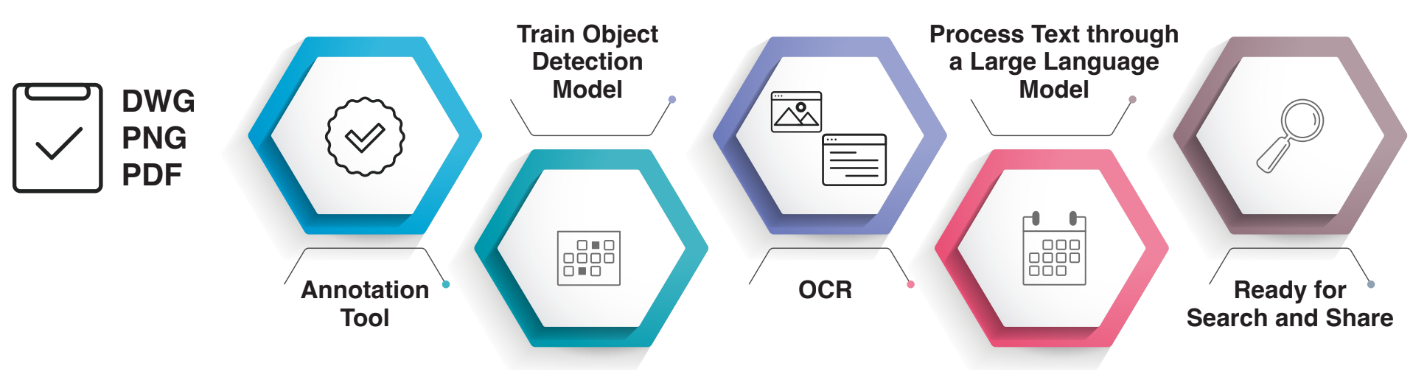
In such scenarios, rule-based software alone is insufficient to address this complexity.
Moreover, some drawings are handwritten, while others may be damaged by exposure
to sunlight or water. To effectively address these challenges, robust solutions are
required, as outlined in the subsequent section.