
The following objectives were identified for the project:
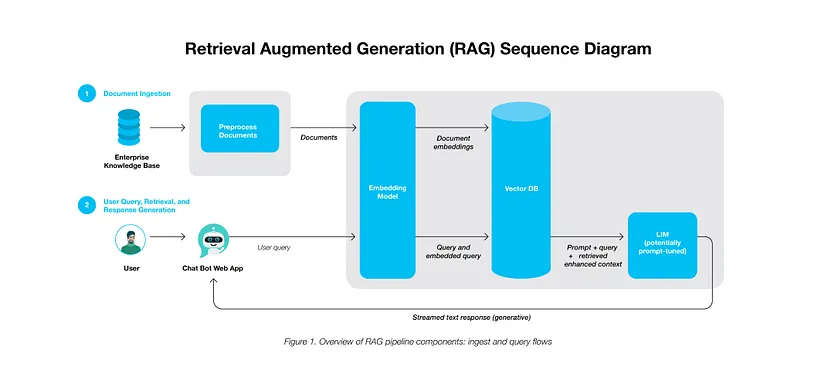
Ingestion: This phase involves the integration of raw data from varied sources such as databases, documents, or live feeds into the RAG system. LangChain’s document loaders serve as conduits for diverse data formats. Source data do not necessarily need to be a standard document (PDFs, text and so on), they support loading data from Confluence, Outlook emails and many more. LlamaIndex also provides a variety of loaders available from LlamaHub.
Pre-processing: Post-ingestion, documents undergo transformations like text-splitting to accommodate the embedding model’s constraints (e.g., e5-large-v2’s token length limit). While this sounds simple, there are several nuances and considerations one needs to keep in mind during this process to get the optimal performance on your data.
Embedding Generation: Ingested data is converted into high-dimensional vectors, facilitating efficient data processing.
Vector Database Storage: Specialized data stores known as vector databases such as Milvus, Pinecone, Chroma and others store these embeddings, optimizing the rapid retrieval of information for real-time interactions.
LLM Integration: Foundational to RAG, generalized LLMs trained on vast datasets utilize the context provided by vector databases to generate accurate responses based on the user query.
Utilizing RAG within LLM solutions offers tangible benefits such as:
RAG paves the way for building LLM systems that are trustworthy, user-friendly, and factually accurate. Explore the RAG Workflow here to get started on building an app on your local machine. This repository provides a tangible starting point for developing an app capable of addressing domain-specific queries with the most current information.